Serverless Java
MicroProfile und JEE in der Cloud

„Serverless“ ist zu einem Buzzword geworden, das man leicht missverstehen kann: „Toll, wir betreiben Software ohne Server!“. Das ist natürlich Quatsch, da auf jeden Fall Server zum Einsatz kommen müssen — am Ende steht immer irgendwo ein Stück „Blech“ in einem Schrank.
Der Unterschied zum herkömmlichen Software-Betrieb liegt darin, wer sich in welchem Umfang um diese Server kümmern muss. In der Vergangenheit haben Konzepte wie virtuelle Maschinen und Container den eigentlichen Server und sein Betriebssystem bereits immer weiter weg abstrahiert. „Serverless“ steht in dieser Folge für eine Betriebsumgebung, in der man den Server und seine Charakteristiken gar nicht mehr wahrnimmt. Man schreibt ein Stück Code und deployt ihn in eine „Serverless Platform“ wie z.B. AWS Lambda oder Azure Functions und das war es. Dieses Modell wird auch FaaS (Function as a Service) genannt.
Beide Plattformen unterstützen auch Java und dieser Ansatz funktioniert erstaunlich gut, besonders um eventbasierte Architekturen umzusetzen. Allerdings folgen AWS und auch Azure dabei einem proprietären Ansatz, sodass Code speziell für eine dieser Umgebungen entwickelt werden muss. Ob sich dabei ein übergreifender Standard ergeben wird, bleibt abzuwarten.
Wie sieht es in diesem Zusammenhang mit dem guten alten Standard JEE bzw. mit seinem jüngerem Bruder MicroProfile aus? Geht das auch serverless? Tatsächlich lässt sich das direkt miteinander kombinieren, da man z.B. den schnell startenden Quarkus mittlerweile sogar direkt als Custom Lambda Runtime deployen kann.
Wenn man es aber lieber etwas konservativer hat, welche Möglichkeiten gibt es aktuell, um JEE- bzw. MicroProfile-Anwendungen in der Cloud möglichst serverless zu deployen?
Eine alte Idee
Der Ansatz, sich nicht um den Server kümmern zu müssen, steckt von Anfang an in der Philosophie von JEE. Man unterschied zu Zeiten von J2EE zwischen unterschiedlichen Rollen wie dem „Product Provider“, der den Application Server bereitstellt, und z.B. dem „Component Provider“, der sich um die Entwicklung der Beans kümmert. Der Application Server wurde also im Idealfall von einem Administrator-Guru betrieben und der Entwickler konnte sich voll auf seinen Code konzentrieren, den er dann in Form von z.B. eines Wars (Web Archive) zur Verfügung stellte.
So weit die Theorie, in der Praxis war diese Abstraktion schon immer leaky, u.a. weil bei der Konfiguration der Application Server jede noch so proprietäre Konfigurationsmöglichkeit ausgeschöpft wurde, mehrere Artefakte pro Server deployt wurden, oder generell das gegenseitige Verständnis gefehlt hat.
Aber die Idee als Entwickler nur ein Artefakt zur Verfügung stellen zu müssen (z.B. eine War- oder Zip-Datei) und das in eine immutable Umgebung zu deployen, ist nach wie vor aktuell und passt sehr gut zu Cloud-Umgebungen und der Idee vom Serverless Computing.
Die Qual der Wahl
Eine sehr direkte Möglichkeit das umzusetzen bietet die aktuell noch nicht öffentlich verfügbare Payara Cloud von den Entwicklern des Payara Application Servers. Hier ist die Grundidee tatsächlich die, sein JEE-Artefakt einfach hochzuladen und dieses wird dann automatisch und für den Nutzer transparent in einem Payara Server betrieben. Das Angebot soll demnächst auf Azure verfügbar gemacht werden.
Eine vergleichbare Möglichkeit bietet Microsoft direkt in seinem Azure App Service. App Service ist der generelle Dienst in Azure, um auf einfache Art Anwendungen unterschiedlichster Laufzeitumgebungen in der Cloud zu deployen. App Service bietet tatsächlich neuerdings auch an, direkt in einen JBoss Stack zu deployen und kommt damit der Idee von serverless JEE Deployments auch sehr nahe. (Der Pendant zu App Service bei AWS nämlich Beanstalk bietet für direktes Deployment von Java-Anwendungen aktuell nur ein klassisches plain Java Deployment an, oder eines, das auf einem Tomcat-Stack basiert.)
Darüber hinaus gibt es eine verwirrende Anzahl von Möglichkeiten eine Java Anwendung in der Cloud (wie betrachten dabei erst mal nur Azure und AWS) zu deployen. Angefangen mit den Varianten, bei denen man erst selbst einen Application Server auf einer virtuellen Server Instanz installieren muss, z.B. Virtual Machines (Azure) bzw. EC2 (AWS), bis hin zu hoch flexiblen, aber auch komplexen Setups über gemanagte Kubernetes Umgebungen wie AKS (Azure) und EKS (AWS).
Bleiben wir daher etwas bei den „mittleren“ Services wie dem erwähnten Azure App Service oder dem AWS Pendant Beanstalk, da diese Services eingermaßen benutzerfreundlich sind und oft die beste Wahl, um mit geringem Aufwand einfache Anwendungen zu betreiben.
Reale Deployment-Möglichkeiten
Eine Möglichkeit eine JEE- bzw Microprofile-Anwendung in Diensten wie App Service oder Beanstalk zu deployen ist, ein Überjar aus Anwendungscode und Application Server zu bauen und dieses als simple Java-Anwendung auszuliefern. Siehe dazu meinen Artikel zu Azure und Thorntail (Thorntail ist quasi der Vorgänger von Quarkus). So erhält man immer noch ein einfaches Deployment, in dem der Anwendungsserver sozusagen in einem Stück mitdeployt wird. Das ist ein recht pragmatischer Ansatz, wie er ähnlich auch beim verbreiteten Spring Boot praktiziert wird. Ein Nachteil ist, dass man jedesmal den kompletten Server mitdeployen und gegebenenfalls hochladen muss, obwohl sich daran meist nichts geändert hat.
Eine andere Variante kommt ins Spiel, wenn man seine Anwendung in einem (Docker-)Container laufen lassen möchte. So ein Deployment wird sowohl von App Service als auch Beanstalk unterstützt. Und das ist auf jeden Fall eine sehr interessante Option, wenn es um die richtige Mischung aus Abstraktion, Wiederverwendung und Komplexität geht. Je nachdem welche Variante man wählt, kann allerdings die Größe des zu deployenden Artefakts dabei variieren.
Schauen wir uns daher an, wie ein Deployment einer Microprofile-Anwendung mit Beanstalk und Docker aussehen könnte.
Microprofile mit Beanstalk & Docker
Bei der Umsetzung des Beispiels soll zum Vergleich sowohl Wildfly als auch Quarkus zum Einsatz kommen. Um auf Besonderheiten der Konfiguration einzugehen, wird die simple Beispiel-Anwendung dabei auch einen Datenbankzugriff auf eine SQL-Datenbank (Postgres) beinhalten. Dabei handelt es sich um keine Einführung zu den Themen AWS, Wildfly, Quarkus oder Microprofile im Allgemeinen, sodass eine gewisse Grundkenntnis vorausgesetzt wird.
Die POM
Die Projektstruktur für Quarkus samt der Maven POM-Datei kann man sich ganz einfach mit dem Quarkus Maven-Plugin erzeugen. Danach muss man die nötigen Extensions als Dependencies einfügen, oder man lässt sich das alles auf der Website generieren.
mvn io.quarkus:quarkus-maven-plugin:2.6.0.Final:create -DprojectGroupId=de.poro -DprojectArtifactId=quarkus-beanstalk -DclassName="de.poro.bt.HelloResource" -Dpath="/hello"
Dieses Kommando erzeugt die komplette Projektstruktur und sogar einen ersten (leeren) Service. Die für uns nötigen Quarkus Extensions sind folgende:
Bei Wildfly sieht die POM herkömmlicher aus: man hat als „Managed Dependencies” die Abhängigkeit zu Wildfly-JakartaEE und -Microprofile und ansonsten als „Provided Dependencies” im Wesentlichen nur die JEE API bzw. die von MicroProfile Health (dazu später).
In beiden Fällen muss ein Artefakt bereitgestellt werden, dass später zu Beanstalk hochgeladen wird. Dazu wird das Assembly-Plugin genutzt. Zu seiner Konfiguration kommen wir später.
Die Wildfly-POM baut ein klassisches War, das nur den Anwendungscode und die Konfiguration beinhaltet. Für Quarkus erzeugt das Quarkus-Plugin ein sogenanntes Fast-Jar. Hierbei wird alles, was später gebraucht wird unter target/quarkus-app abgelegt.
Beginnen wir mit dem simplen REST-Service, der keine weiteren Abhängigkeiten hat:
Für Wildfly benötigt man noch einen REST-Initialisierer. In Quarkus ist das nicht nötig. Ein eventuell gewünschter Context-Root kann über Properties angegeben werden, ansonsten sind die Services direkt unter / verfügbar. Für Wildfly gilt zu beachten, dass RESTEasy (die JAX-RS Implementierung) es nicht erlaubt, statische Ressourcen im selben Kontext zu deployen (z.B. eine index.html).
Ein weiterer Service soll als Beispiel Einträge aus der Datenbank auslesen. Die Tasks-Resource gibt also eine Liste von Tasks, die in der Datenbank hinterlegt sind, als Json-Struktur zurück. Dazu injiziert sie einen Service der „ApplicationScoped” ist. Man beachte, dass wir keine EJB-Annotationen benutzen (wie z.B. @Stateless).
Im Taskservice wird der EntityManager iniziert. Das mag angesichts der Tatsache, dass der Service als „ApplicationScoped“ quasi als Singleton existiert, Fragen bezüglich der Thread-Sicherheit aufwerfen. Allerdings sind Container-gemanagte EntityManager diesbezüglich sicher.
Es werden hier also keine EJBs aus dem JEE-Standard genutzt, für den Datenbank-Zugriff kommt allerdings JPA zum Einsatz, was Teil von JEE ist, da MicroProfile dafür keine eigene Spezifikation hat. Das von Quarkus mitgelieferte handliche Panache wird hier der Einheitlichkeit halber nicht genutzt. Grundsätzlich sollte man bei seinem Einsatz berücksichtigen, dass es kein Standard ist, und daher nicht kompatibel und seine Lebenszeit von Redhats Engagement abhängt.
Konfiguration
Was die Konfiguration betrifft, ist Quarkus deutlich im Vorteil. Beim Start wird standardmäßig eine Datei „application.properties” in src/main/resources berücksichtigt. Hier kann man z.B. die DataSource definieren. Die gilt dann auch als Default, sodass man beim Einsatz des EntityManagers keine DataSource (z.B. über „unitName“) angeben muss. In Wildlfy muss darüberhinaus die Persistence Unit (hier „sample”) über eine klassische „persistence.xml” definiert und im War mitgepackt werden.
Hier die Konfiguration des Quarkus:
Wildfly ist diesbezüglich deutlich umständlicher zu konfigurieren. Einerseits muss die Datei „standalone.xml” erweitert werden, um in unserem Fall die DataSource einzutragen, andererseits muss auch ein benutzerdefiniertes Modul erzeugt werden, dass den JDBC-Treiber beinhaltet.
Docker
Beim Aufbau des Dockerfiles ist wieder ein klarer Unterschied zu sehen. Beinhaltet im Wildfly-Fall das Base Image bereits den Application Server, ist es für Quarkus nur das RedHat Universal Base Image samt dem Java 11 JDK. Der Application Server wird ja lokal und nur mit ausgewählten Komponenten mitgepackt. Damit wird das in die Cloud zu ladende Artefakt deutlich größer als bei Wildfly.
Das Dockerfile für Quarkus:
Und hier für Wildfly:
Dazu müssen unterschiedlich Dateien ins Docker-Image aufgenommen werden. Für Quarkus sind das im Wesentlichen die Dateien im Verzeichnis target/quarkus-app. Für Wildfly wäre es eigentlich nur die War-Datei, wenn da nicht die Kleinigkeit der Konfiguration wäre. Einerseits muss also der JDBC-Treiber an die richtige Stelle ins Verzeichnis modules kopiert werden, anderseits muss auch die „standalone.xml” (bzw. in unserem Fall die „standalone-microprofile.xml”) manipuliert werden. Ich hab mich der Einfachheit halber entschieden, die gesamte Datei auszutauschen. Damit wird man allerdings sofort von der eingesetzten Wildfly-Version abhängig. Eine schickere Variante wäre, z.B. mit XmlStarlet, die Datei dynamisch anzupassen. Das würde allerdings wiederum bei jedem Start der Container-Instanz passieren und ist der Startgeschwindigkeit nicht unbedingt zuträglich.
Damit kann man die Images zum Ausprobieren lokal bauen und laufen lassen:
docker build -f Dockerfile -t sample/microprofile-beanstalk .
docker run -i -rm -p 8080:8080 -name microprofile-beanstalk sample/microprofile-beanstalk
Beanstalk
Wie kommt die Anwendung nun nach Beanstalk?
Beanstalk bietet mehrere Möglichkeiten des Deployments, z.B. per CLI oder CloudFormation. Um das Beispiel überschaubar zu halten, nutzen wir aber nur die Web-basierte Admin-Konsole. Wie schon erwähnt, erwartet Beanstalk für eine Docker-Anwendung eine einzelne Zip-Datei zum Hochladen. Diese Zip muss das Dockerfile beinhalten und alle Dateien, die darin referenziert werden.
Um dieses Zip-Archiv zu bauen, verwenden wir das Assembly-Plugin von Maven. Die dazugehörige Konfigurations-Datei für Quarkus sieht so aus (die Wildfly-Variante ist sinngemäß ähnlich):
Ist die Zip-Datei gebaut, wählt man in der AWS-Web-Oberfläche den Beanstalk-Service und klickt (in der englischsprachigen UI) auf „Create new Environment“. Dann wählt man die Option „Web Server Environment“. Im darauffolgenden Dialog kann man einen Application- und Environment-Namen angeben, die Angabe einer Web-Domäne ist optional. Hat man keine eigene, wird immer eine Subdomäne aus der Domäne „<region>.elasticbeanstalk.com” verwendet. (Die Verwendung einer eigenen Domäne muss gegebenenfalls erst in Route 53 aktiviert werden). Als „Platform” wählt man Docker (die Details dazu lässt man, wie sie voreingestellt sind). Unter Application Code wählt man dann „Local File“, was einem zu einem Auswahldialog führt, wo man dann die lokal gebaut Zip-Datei auswählt.
Über die Angabe eines Versionsnamen kann man unterschiedliche Versionen unterscheiden und wenn gewünscht auch wiederherstellen.
Dann muss man die Einstellungen bestätigen und die Anwendung wird hochgeladen und gebaut!
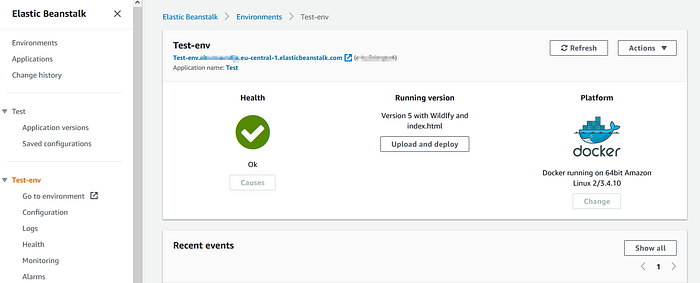
Im Idealfall hat das fehlerfrei funktioniert und die automatischen Healthchecks sind grün. Diese Healthchecks rufen standardmäßig den Root-Pfad der Anwendung auf und erwarten einen 200er Response (z.B. von einer index.html).
Geht was schief, kann man sich bei ausgewählter Umgebung über das Submenü „Logs“ die Log-Dateien geben lassen. Das ist etwas umständlich, daher kann man z.B. im Submenü „Configuration“ im Abschnitt „Instances“ eine Anpassung vornehmen, um die Logs auch nach CloudWatch zu schreiben.
Neue Versionen der Anwendung können danach einfach durch Angabe der hochzuladenden Datei hochgeladen werden.
HealthChecks
Kommen wir noch mal zum Thema Healthchecks. Microprofile unterstützt das einfach Erstellen von Healthchecks über Annotationen, hier z.B. für einen Liveness-Check :
Das Aufrufen der Checks ist allerdings von Server zu Server etwas unterschiedlich. Sind die Healthchecks in Quarkus unter der URL <host>:<standard-port>/q/health also z.B. „localhost:8080/q/health” verfügbar, ist es bei Wildfly <host>:<management-port>/health also z.B. „localhost:9990/health”. Um den Management-Port aus Docker zu nutzen, muss er zusätlich beim Starten der Instanz verfügbar gemacht werden (Parameter „-p”).
Um diese Services in Beanstalk als Healthcheck zu nutzen, muss man über die Konfiguration im Abschnitt „LoadBalancer” unter „Processes” der Healthcheck-Pfad und Port angepasst werden.
Exkurs: Die Datenbank
Eine Sache haben wir bis jetzt vernachlässigt, und zwar die Datenbank. Beanstalk bietet zwar die Möglichkeit, ein RDBMS direkt mitzukonfigurieren, hier wollen wir aber den herkömmlichen Ansatz betrachten, nämlich eine relationale Datenbank separat in AWS zu verwalten.
Dazu wurde im AWS RDS Service eine Postgres-Datenbank erstellt. Dabei kann man beim Anlegen einige Optionen auswählen, auf die hier nicht weiter eingegangen wird (das meiste kann man zum Ausprobieren auf der Vorauswahl stehen lassen). Die erzeugte Datenbank beinhaltet eine Datenbank-URL, die als Host in der JDBC-Verbindungs-URL genutzt werden muss.
Der wichtige Punkt dabei ist, dass die SecurityGroup (Im Grunde eine Art virtuelle Firewall), in der die Datenbank läuft, Inbound-Rules enthalten muss, welche eingehenden Traffic auf dem Postgres-Port (default 5432) erlaubt (am besten für IPv4 und IPv6) und dass die Datenbank im selben VPC läuft wie die Beanstalk-Anwendung. Damit ist die Datenbank von der Anwendung aus erreichbar (Wenn es sich um unterschiedliche VPCs handelt, braucht man zusätzliche Routing Rules).
Wie kann man aber das Schema in der Datenbank anlegen? Da man die Datenbank in der Regel nicht von außen (public) erreichbar haben möchte, muss man andere Wege gehen. Man könnte erwarten, dass man zumindest rudimentären Zugriff zum Erzeugen von Tabellen über die Web-Konsole erhalten würde. Aber das wird leider nicht unterstützt. Im Enterprise-Umfeld wird man vermutlich ein VPN einrichten, sodass man die Datenbank auf diesem Weg auf gewohnte Weise erreichen kann. Eine andere Option ist die Einrichtung eines Bastion Hosts. Dazu erzeugt man eine (kleine) EC2-Instanz. Bei der Einrichtung kann man einen persönlichen Key erzeugen lassen, den man anschließend herunterlädt und sicher abspeichert. Die Instanz muss in einer SecurityGroup laufen, die den Zugriff von außen (e.v. eingeschränkt auf spezielle IP-Adressen) zulässt. Auf diese EC2-Instanz kann man jetzt unter Angabe der Schlüsseldatei eine SSH-Sitzung aufmachen und mit Hilfe von SSH Tunneling auf den DB-Server zugreifen. Einige Tools wie z.B. der Postgres pgAdmin unterstützen das out-of-the-Box, sodass man hier nur den Bastion Host, den User („ec2-user“) und die Schlüsseldatei angeben muss.
Fazit
Moderne Java-Anwendungen, die auf Basis von Microprofile oder JEE gebaut sind, lassen sich gut in der Cloud deployen und betreiben. Dabei kommt je nach Wahl des Modells mehr oder weniger „Server“ zum Einsatz. Komplett „Serverless“-Deployments sind dabei noch eher selten. Es ist aber denkbar, dass auch diese Varianten in Zukunft noch deutlich mehr direkte Unterstützung erfahren werden.
